
Solutions
An Introduction to Azure Data Lake Analytics

Dibyendu Dasgupta
Technical Consultant in Data & AI
November 16th, 2017
So, you have been running a nice company portal – cool product catalogue, backed by market leading e-commerce engine, facilitating the smoothest online purchase as possible for your customers.
And, you have been collecting purchase data from your portal all along and storing it into your company data warehouse, producing many useful corporate reports and analytics that have been used effectively throughout your organization.
That’s all excellent and the just the way it should be!
Are you missing anything though?
What about the information about how much time a customer spent on the product pages that have been on promotion this month? Or, which are the products that the customers spent quite a bit of time checking out but never end up purchasing? Which geographical region these customers belong to? What are their age groups? Have they arrived under a loyalty program? Are they male or female?
Or, what about some housekeeping data instead? How’s your portal really performing? How long it takes each page to load? How often the user hits the browser’s back or stop button and how much data is transmitted before the user moves on?
Data like the above is called Clickstream data. Even a few years back this sort of data were “nice to have” for most of the organizations. The issue, obviously, was resource. Unless it’s a large organization capable of chipping in very serious looking pieces of hardware and associated infrastructure, most places folded in their cards on this – and quite rightly so! Depending upon how big and complex the data is, the available processing power and storage would have been chewed up in no time!
Now that Microsoft Azure is here, a virtually limitless storage and processing power have come into the grasp of even the mid to small ranged organisations. Azure Data Lake has brought in a revolutionary change in the field of big data analytics.
So, what exactly is the big data analytics? What is data lake and what does it have to do with the big data analytics?
Here’s what Google Dictionary says about big data:
“extremely large data sets that may be analysed computationally to reveal patterns, trends, and associations, especially relating to human behaviour and interactions”
As you see, the above clickstream data falls into this category – so are the periodic signals emitted by diverse types of sensors and other devices (called IOT – Internet of Things). The large continuous set of data produced by these devices can now be stored and analysed to make a meaning out of them – easily and relatively inexpensively. This is essentially “analysis on the go” and that is exactly what the data lake provides for.
What is Azure Data Lake? As per the definition on the Microsoft website, data lake is an enterprise-wide hyper-scale repository for big data analytics workloads. It enables you to capture data of any size, type, and ingestion speed in one single place for operational and exploratory analytics.
Azure Data Lake Store provides unlimited storage and is suitable for storing a variety of data for analytics. It does not impose any limits on account sizes, file sizes, or the amount of data that can be stored in a data lake. Individual files can range from kilobyte to petabytes in size making it an excellent choice to store any type of data. Data is stored durably by making multiple copies and there is no limit on the duration of time for which the data can be stored in the data lake.
In the world of data lake, the traditional method of ETL (extract-transform-load) of data has been replaced by the approach of load-extract-transform. This “load first” approach has originated from the fact that we can load virtually any type of data (typically unstructured data) into the data lake. This is in turn possible because the storage is unlimited and is cheap.
So, be it unstructured data such as electronic signals from sensors and devices, clickstream data, web feed, audio-visual transmissions, data out of social media such as Facebook or Twitter OR structured relational data from the legacy applications, we can quickly and easily capture everything in one place.
Once stored, we have several ways to transform and analyse the data (see later). Data lake is particularly tuned from ground up to provide real time analysis of the captured data.
The diagram below schematically shows the functionality of the data lake:
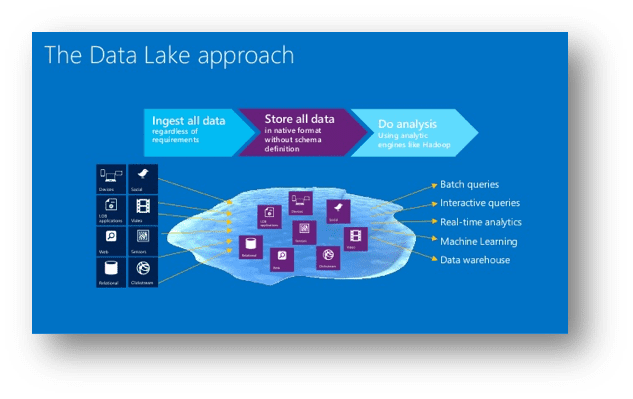
Now, a bit of “under the hood” stuff and a few jargons to get familiar with – Azure Data Lake is built on top of a Java based high performance distributed file system storage called HDFS (Hadoop Distributed File System). Simply speaking, it can store billions of files across a cluster of up to 4,500 servers!
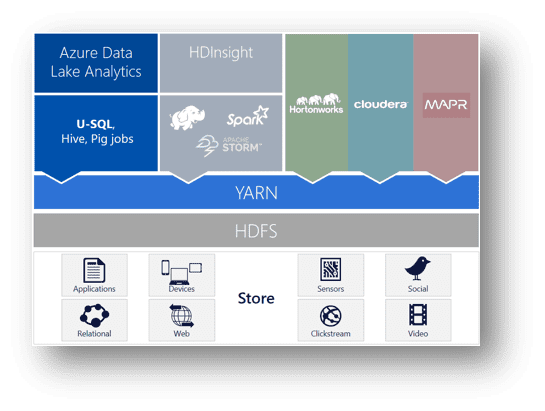
The cluster is managed by an Apache Hadoop technology called YARN (Yet Another Resource Negotiator).
On top of these resides the analytics capability of data lake. Typically, in a Hadoop environment (developed by Hortonworks and provided by Cloudera), one can perform real time data analysis using the HDInsight service. This, in turn, uses services like Spark and Storm. MapReduce is another critical core component of Hadoop – it facilitates the distributed processing of massive unstructured data sets. Together, all these provide for a “low level” way of implementing data analytics. This, although very powerful, can be quite complex to put together, especially if you have been a traditional Microsoft shop – there’s quite a bit of steep learning curve involved!
Enters Azure Data Lake Analytics (ADLA) – the newest kid in the block. Suffice to say – Microsoft has done a fantastic job in hiding many of the complexities inside and providing a nice, clean “high level” approach for you to perform big data analysis.
ADLA is an on-demand analytics job service to simplify big data analytics. You can focus on writing, running, and managing jobs rather than on operating distributed infrastructure. Instead of deploying, configuring, and tuning hardware, you write queries to transform your data and extract valuable insights. The analytics service can handle jobs of any scale instantly by setting the dial for how much power you need. You only pay for your job when it is running, making it very cost-effective.
ADLA is optimized to work with Azure Data Lake – providing the highest level of performance, throughput, and parallelization for your big data workloads. Data Lake Analytics can also work with Azure Blob storage and Azure SQL Database.
ADLA is a cost-effective solution for running your big data workloads. You pay on a per-job basis when data is processed. No hardware, licenses, or service-specific support agreements are required. The system automatically scales up or down as the job starts and completes, so you never pay for more than what you need!
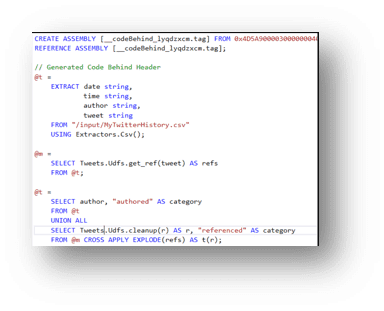
ADLA also includes U-SQL, a language that unifies the benefits of SQL with the expressive power of user code. U-SQL’s scalable distributed runtime enables you to efficiently analyse data in the store and across SQL Servers in Azure, Azure SQL Database, and Azure SQL Data Warehouse. You can use it to manage Hive (HDInsight cluster, actually) and create Pig jobs (to create behind the scene Hadoop programs).
The construct of U-SQL is a nice blend of traditional SQL and C#, something you should be quite familiar with, if you have been a Microsoft shop.
See a quick sample below:
If there’s still a bit of frown on you, especially about the security around all this, be rest assured that Azure Data Lake works with the Azure Active Directory (AAD) service to seamlessly provide authentication and authorization around all your data.
So, which are the organisations that are using data lake analytics successfully?
The American casual dining chain Chilli’s have been a fore runner in the field of using data analytics to stream line business processes. While the general restaurant industry has been in a slump, recording it’s 6th consecutive quarter of traffic decline (down by 3% as of June 2017), Chilli’s has successfully defended a steady growth of 1.39% in the current year. This has been largely possible by analysis of it’s customer behavioural data collected from it’s Ziosk tabletop tablets.

As a result of that data analysis Chili’s has slashed it’s menu by 40%, thereby creating a streamlined menu that is both cost effective and different from it’s competitors.
Data lake analytics has been successfully used in the US population health management systems. LVPEI, a leading eye institute has successfully used data analytics in the field of predicting post-operative activities. Below is a slide of the Microsoft case study on this organisation:

Another health organisation Optolexia has been using big data analytics to provide for the early screening of dyslexia among the school students.

A few more applications of successful data lake analytics:


The biggest application of data lake analytics, however, comes from none other than Microsoft itself. It has amassed a gigantic set of customer behavioural data from it’s Xbox games, Skype, Yammer and Office 365 applications. At any point in time over 10,000 developers are working on this data to produce various sets of corporate-wide reports!
So, is your traditional data warehouse and associated analytics on it’s way out?
Not quite, the analytics on structured data is certainly going to stay. You WILL need the sales figures same time last year OR the breakup of your customer orders across states. However, big data analytics will open up a whole new horizon for you – it will provide insights of your business to you that you have not perceived so far. This would a gold mine of information at your fingertip – and as we all know, information is the King!
Want more help with Azure? Learn about our Microsoft Azure services.
Bibliography:
- Microsoft Data Analytics Overview
https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-overview - Azure Data Lake & Azure HDInsight Blog
https://blogs.msdn.microsoft.com/azuredatalake/ - Population Health Management using Azure Data Lake Analytics and Power BI
by
Danielle Dean
https://www.youtube.com/watch?v=iwX3xuWooPU


